Let’s Panic: ESXi failover not working, using Static LAG/etherchannel
There was once… a customer who was concernced about the network-wise failover on the ESXi-level, which was not working as he expected it to. To shed some light on the complete scenario…
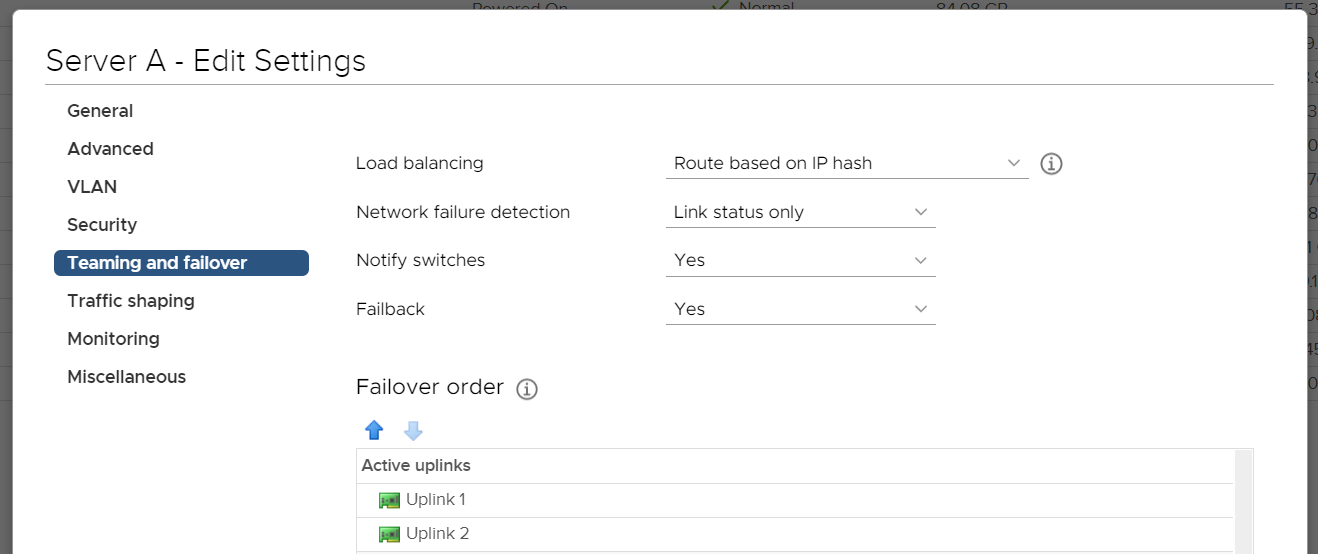
Configuration
The configuration is pretty simple:
- The switch is
vSwitch0 - As
Failover orderthere are two vmnic adapters configured as active. (Let’s say vmnic0 and vmnic1) Load balancingisRoute based on IP hash(Static LAG/etherchannel/trunk set on physical switch)Network failure detectionisLink status onlyNotify switchesisYes.
Taking above into consideration: When disabling one of the two active vmnic adapters on ESXi using esxcli network nic down -n vmnicX you would expect a failover to occur – don’t you? The truth is: Not necessarily. Let’s go into detail…
Components
We do have three major components playing together:
- pSwitch -> pServer: The physical switch, which is sending traffic from somewhere else to the physical server running ESXi.
- pServer -> pSwitch: The physical server running ESXi, sending traffic to the physical switch via driver via the pNIC.
- Static LAG: On both ends we do have static LAG/etherchannel/trunk in use.
Failover Scenarios
On top of that, we basically have to distinguish between two failover scenarios which might occur:
- Failover based on physical reasons, like physical switch outage, broken cable, plugging the cable, etc. In this situation however the physical link state on the physical network card within the server, as there’s no more active link nor power on the cable. This is being reported via the driver to VMware ESXi.
- Failover based on software reasons, like setting the vmnic0 as down – for instance by using
esxcli network nic down -n vmnic0.
What happens…
In both scenarios, the vmnic state is changed to down. However there’s one major difference:
- In the first scenario the physical server as well as the physical switch are aware about the link state being down. No traffic is being sent from the ESXi side to the switch or vice-versa.
- In the second scenario however, only the software-based vmnic0 is being taken down. While ESXi reports this to the driver, this doesn’t necessarily mean that the driver/firmware took action taking down the physical link/port on the physical network card.
Let’s assume the physical NIC port is not taken offline. So we end up in following scenario:- On the physical server: ESXi initiates a network-failover on the vSwitch0, as one active vmnic adapter is taken down logically. The other active vmnic is used, as intended.
- On the physical switch: As the physical link state of the specific network card port of the physical server hasn’t changed, the physical switch still sees the link as up and active, as there’s still power on the cable. Assuming both vmnic’s are still functional.
- So when traffic is being sent from the physical switch to the physical server, the switch might do its actual configured load balancing on the static LAG and sending traffic on the cable where the vmnic0 was logically disabled. As vmnic0 is disabled, any traffic will be discarded. Resulting in noticable network issues.
In the end…
Key takeaway: In this specific scenario, this is indeed "expected" behavior.
It’s Important to note that this is NOT a "wrong behavior" or a "issue" – this is bascially "as expected". As per Static LAGs standard, there is no active heartbeating – so as long as the physical link state is up, the individual physical port is classified as "working". In different words: Traffic is being sent via the static etherchannel – with load balancing taking place – in both directions as long as the physical link is up.
This is where LACP (802.3ad) might meet the expectations: It does offer an active keep-alive mechanism to detect failed connectivity on individual ports on a more granular level. (LACP can be configured on Virtual Distributed Switches.)
